
エッジAI向けアクセラレータ
- Tiling & Layer fusionによる12TOPS/Wの実現
- スケーラブルな構成でFPGAからASICまで幅広くサポート
- デンソーテン社の軽量エッジAIとのコラボレーション
◆ Tiling & Layer fusionによる高い電力効率を実現
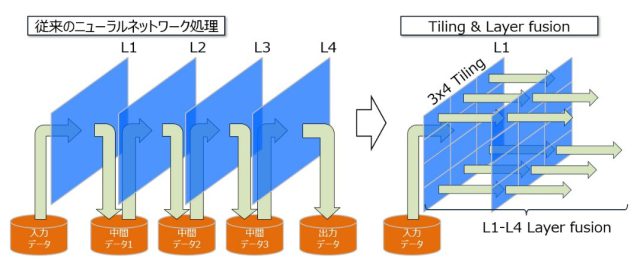
従来のニューラルネットワーク処理では、レイヤ処理毎に中間データを消費電力の大きい外部メモリに退避しており、これが電力効率低下の原因となっていました。MLシリーズは、入力データを分割(Tiling)し、分割したデータ毎に複数のレイヤ処理の入出力を連結(Layer fusion)して処理することにより、中間データの外部メモリへの退避を削減し、電力効率を向上することが可能です。これにより、VGG16、MobileNet、ResNetといったニューラルネットワークを12TOPS/Wの電力効率(7nm世代SoC実装時)で実行できる見込みです。
MLシリーズは、ハードウエアランダム故障を検出する診断回路を内蔵する構成も提供しており、外部に特殊な診断回路を追加することなく、セーフティクリティカルシステムにAIを適用することが可能です。
◆ スケーラブルな構成でFPGAからASICまで
MLシリーズでは、スケーラブルな構成により限られたリソースで実装を行うFPGAから、AIとしての性能を追求するASICまで幅広い実装に対して最適に対応します。
| MAC演算器数 | 名称 | ターゲット | 想定周波数(Hz) | 性能(TOPS) |
| 128 | MLm71 | FPGA | 150M | 0.0384 |
| 256 | MLm81 | FPGA | 150M | 0.0768 |
| 512 | MLm91 | FPGA | 150M | 0.1536 |
| 2048 | ML021 | ASIC | 620M | 2.32 |
| 4096 | ML041 | ASIC | 620M | 4.63 |
◆ デンソーテン社の軽量エッジAI(ニューラルネットワーク)とのコラボレーション
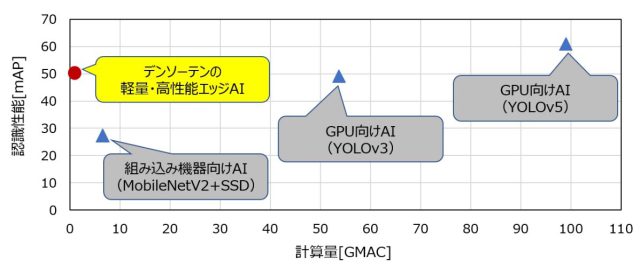
さらにデンソーテン社の「軽量エッジAI(ニューラルネットワーク)」を組み合わせることによって、演算精度を劣化させることなく演算量を1/7に削減することで、消費電力を0.06Wまで低減できます。
物体検出AIは物体を識別するための特徴を抽出する特徴抽出部と、特徴量に基づいて物体を識別するオブジェクト検出部に分かれます。いずれも畳み込み演算(Convolution)が使われるため、非常に多くの演算が必要となります。デンソーテン社では、特徴抽出部の一部の演算を近似演算(Separable Convolution)に置き換えるなどにより、小さな特徴抽出部とマルチクラスの高精度オブジェクト検出部からなるハイブリッドAIを構築しています。これにより、少ない演算量で高精度な物体検出を可能にしています。
今回共同開発した低消費電力物体検知ソリューションを、車載製品や、セキュリティカメラ、FA等の様々な組込み機器へ展開を図り、安心安全な社会の実現、および低消費電力による環境負荷低減に貢献していきます。
NSITEXE Akaria
Akaria Processor
Akaria Domain Specific Accelerator: DR Family